Daniel Kehlmanns Ruhm ist ein in neun Geschichten erzählter Roman. Ruhm lebt von den Verbindungen, den wechselseitgen Verstrickungen der jeweiligen Protagonisten: Während in der einen Geschichte die Reise des Schriftstellers Leo Richter durch Südamerika geschildert wird, handelt eine andere von dessen berühmtester Romanfigur Rosalie, die wiederum mit einer anderen fiktiven Figur, Lara Gaspard, verwandt ist. Von Lara Gaspard, deren Alter Ego Elisabeth zu sein scheint, träumt wiederum Mollwitz, ein Netzfreak und Angestellter in einer Telekommunikationsfirma, aus deren internen Intrigen letzlich die doppelte Nummernvergabe erwächst, bei der alles seinen Anfang nimmt und Ebling das Leben des berühmten Schauspielers Ralf Tanners zerstört.
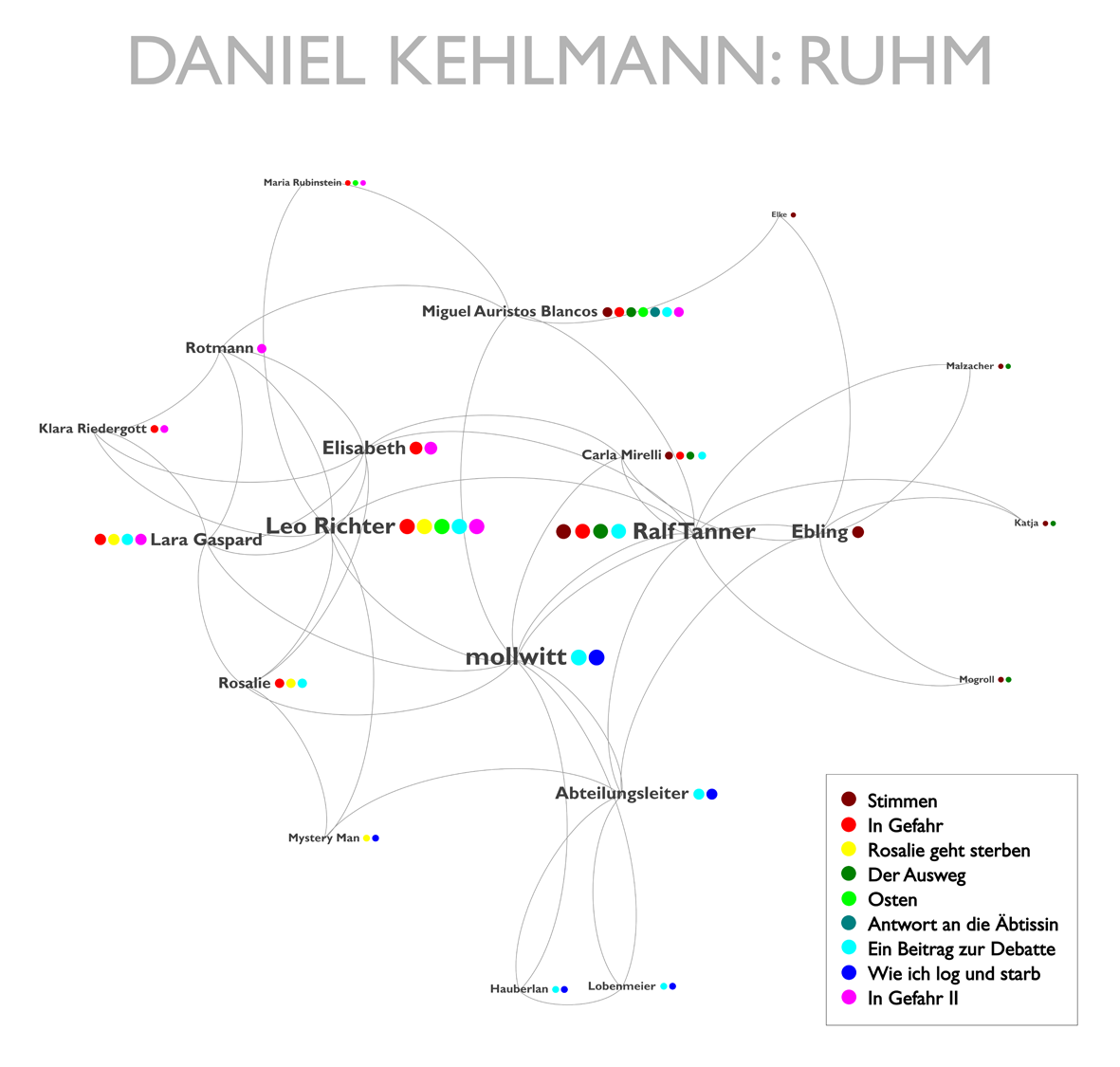
Möchte man ein Netzwerk visualisieren, dann sind viele Entscheidungen zu treffen, allen voran die Entscheidung, welche Personen in die Darstellung aufgenommen werden sollen. Alle? Nur die namentlich Genannten? Oder nur diejenigen, welche die Handlung vorantreiben? Die Protagonisten? Auch diejenigen, mit denen die Protagonisten in einer engen Beziehung stehen? Man sieht, es ist unumgänglich eine präzise Fragestellung zu formulieren, um sich nicht im Detail zu verlieren. Mich interessieren diejenigen Figuren einer Geschichte, die mit Figuren einer anderen Geschichte verbunden sind, so dass jede von mir aufgenommene Figur in mindestens zwei verschiedenen Geschichten vorkommen muss. Ausnahmen von dieser Regel bilden dabei Figuren, die Brücken schlagen, wie dies z.B. im Fall von Eblings Ehefrau Elke der Fall ist, die diesen indirekt mit dem Autor Miguel Auristos Blancos verbindet, da sie eines dessen Bücher liest.
Der Name jeder Figur dient in meiner Netzwerkvisualisierung als Knotenpunkt. Den namenlosen und äußerst mysteriösen ‚Taxifahrer‘ habe ich dabei in Anlehnung an die Forschungsliteratur zu David Lynchs Spielfilm LOST HIGHWAY, in dem ein ähnlich mysteriöser Mann, der die Fäden zu ziehen scheint, auftaucht, Mystery Man getauft. Die Schriftgröße aller Namen ist abhängig von der Anzahl der Verbindungslinien des Knotens, so dass stärker vernetzte Figuren nicht nur stärker ins Zentrum rücken, sondern auch deren Namen in einer größeren Schrift erscheinen. Um zu zeigen, welche Figur aus welcher Geschichte mit welcher Figur aus einer anderen Geschichte verbunden ist, habe ich jeder Geschichte zudem eine Farbe zugeteilt und den Figurennamen jeweils einen Kreis in der entsprechenden Farbe zur Seite gestellt, so dass man sieht, welche Figuren miteinander verbunden sind und in welchen Geschichten sie agieren.
Das Netzwerk habe ich mit gephi erstellt, die exportierte Vektorgrafik mit inkscape nachbearbeitet und das Ergebnis schließlich als .png abgespeichert.
Schreibe einen Kommentar